

Authors:
(1) Busra Tabak [0000 −0001 −7460 −3689], Bogazici University, Turkey {[email protected]};
(2) Fatma Basak Aydemir [0000 −0003 −3833 −3997], Bogazici University, Turkey {[email protected]}.
Table of Links
- Abstract and Introduction
- Background
- Approach
- Experiments and Results
- Discussion and Qualitative Analysis
- Related Work
- Conclusions and Future Work, and References
3 Approach
This section outlines the methodology employed in this study to address the research objectives. It is divided into several sections, each focusing on a crucial step in the process. The section begins with an overview of the data collection, which details the sources and methods used to gather the necessary data for analysis. The preprocessing describes the steps taken to clean and transform the raw data into a format suitable for further analysis. Next, feature extraction explains the techniques used to extract relevant features from the preprocessed data, capturing essential information for the subsequent classification. Finally, the classification discusses the algorithms and models employed to classify the issues based on their assigned labels.
3.1 Data Collection
Our raw data come from the issues of five industrial projects documented on Jira software of a company that offers solutions in the fields of business-to-business (B2B) display systems for televisions, namely, hotel TV systems and advertising and promotional display systems. The company[1] is a home and professional appliance manufacturer with 18 subsidiaries specializing in electronics, large appliances, and information technology and it is Europe’s leading television manufacturer, accounting for a quarter of the European market with over eight million units sold in a year.
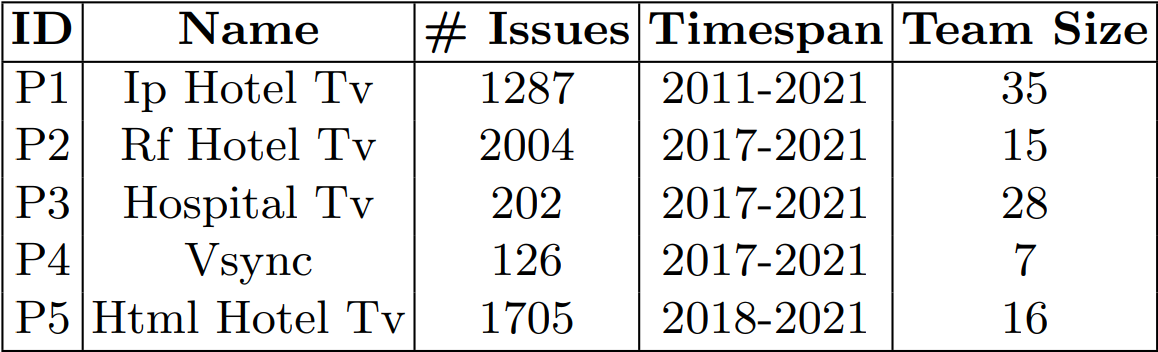
Table 1 summarizes the raw data. We use issue reports from five web application projects, all of which are two-sided apps with a management panel and a TV-accessible interface. The mission of the IP Hotel TV project is a browser-based interactive hospitality application used by hotel guests in their rooms. There is also a management application for managing the content that will be displayed. This is the company’s first hospitality project, which began in 2011 and is still in use today by many hotels. The project Hospital TV is a hospital-specific version of the IP Hotel TV application. It is compatible with the Hospital Information Management System (HIMS), which is an integrated information system for managing all aspects of a hospital’s operations, including medical, financial, administrative, legal, and compliance. The Rf Hotel TV project is a version of the Ip Hotel TV application that can be used in nonintranet environments. A coax cable is used for communication with the server. The HTML Hotel TV project is a cutting-edge hospitality platform. It will eventually replace the IP Hotel TV project. Instead of using an intranet, this version is a cloud application that works over the Internet. A central system oversees the management of all customers. Customers now have access to new features such as menu design and theme creation. The project Vsync is a signage application that synchronizes the media content played by televisions. Televisions play the media through their own players.
These projects are developed in different programming languages. The project Rf Hotel TV is written in Python using the Django framework while the project Vsync is written in C# and JavaScript using the Angular framework. The rest of the projects are written in pure Javascript and C# using Microsoft technologies such as .Net and .Net Core frameworks.
The number of issues per project ranges from 126 to 2004, and the total number of issues is 5324. The data set contains issue reports submitted between 2011 and 2021, all related to different versions of the applications. The issues are created by users with different roles such as software developers, team leaders, testers, or even customer support teams in the data. Then, they are assigned to workers with different roles and experiences. The number of employees in the projects varies between seven and 35 when the “Creator”, “Reporter”, and “Assignee” columns in the data set are combined.
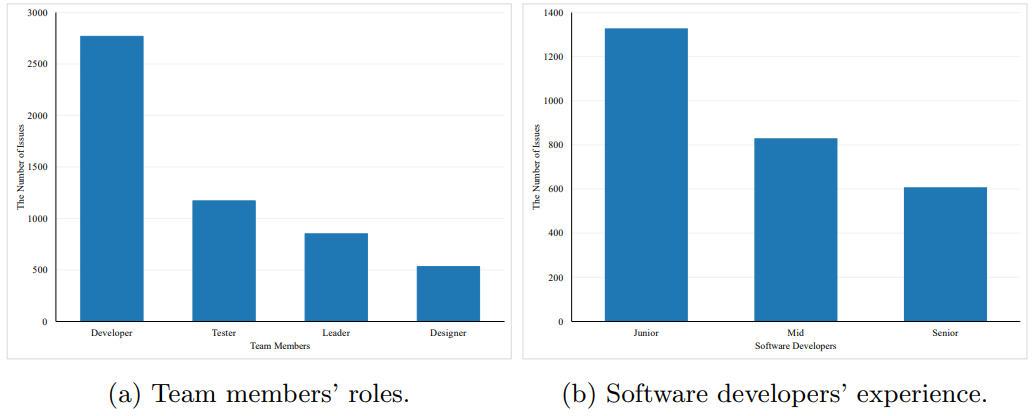
In the original data, the issues are assigned to the individual employees. We removed the names of the individuals to preserve their privacy and inserted their roles in the development team as a new column with the possible values “Software Developer”, “UI/UX Designer”, “Test Engineer”, and “Team Leader”. For the developers only, we also assigned another column indicating their level of expertise as Junior, Mid, and Senior. We inserted this new information in collaboration with the company. Figure 3a depicts the distribution of the assignees over the entire data set. As the first chart shows we can observe that team leaders receive the least number of issues and software engineers receive the majority of them. According to Figure 3b, the distribution of experience among software developers, the issues are primarily assigned to junior-level developers, at most, and senior-level developers, at least.

We directly export the data from the company’s Jira platform in Excel format, including all columns. Table 2 is a small portion of the massive amount of the data available. Although most columns are empty for each row, the tables have a total of 229 columns. To create the issue, required fields like “Summary,” “Description” and “Assignee” are filled, but fields like “Prospect Effort” and “Customer Approval Target Date” are left blank because they aren’t used in the project management.
The issues are originally written in Turkish with some English terms for technical details and jargon. We also translate the issues to English and share our data publicly in our repository[2].
3.2 Preprocessing
Preprocessing is the first step in machine learning, and it involves preparing raw data for analysis as shown in Figure 4. The process starts with exporting all the issues from the selected projects in the Jira tracker system to an Excel file. Once exported, the data needs to be cleaned up to eliminate any rows that have fully empty columns. We eliminate the rows that contain empty assignee columns.
Another issue that needs to be addressed during preprocessing is dealing with missing values. In the Jira tracker system, if the numerical data that will be used as a feature, such as reopen count, is not assigned, it appears as NaN (Not a Number) in the data set. To avoid this problem, the missing values are changed to zero in the entire data set.
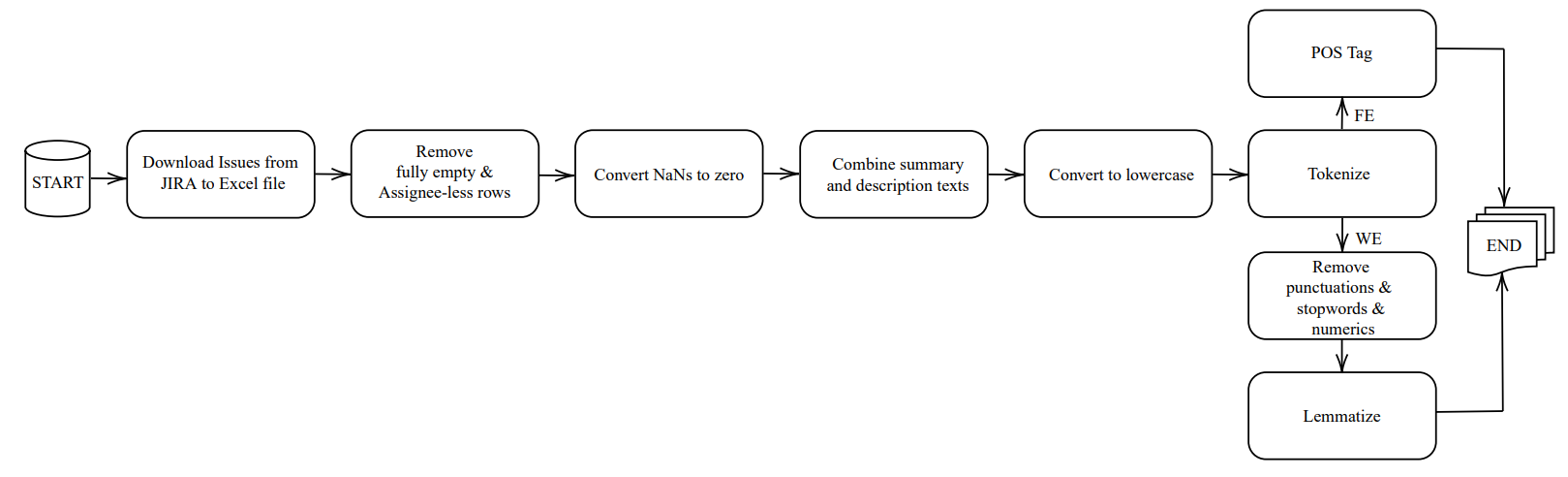
We concatenate two textual parts summary and description into new metadata, which we refer to as issue text. Note that these two fields are available for each issue when an issue report is submitted. We apply a lowercase transformation to ensure consistency in the issue text. This step involves converting all uppercase characters to their corresponding lowercase characters. After the transformation, we tokenize the text into words by splitting it into spaces between words.
For our feature extraction methodology, we do not perform additional text cleaning steps as every word’s feature is essential for our process. We perform Part-of-Speech (POS) tagging after the tokenization step. It involves assigning a POS (such as a noun, verb, adjective, etc.) to each word in a given text. We use Zeyrek library [10] for issue texts in Turkish because it is trained on a large corpus of Turkish text.
For most used word embedding methods, we perform additional text cleaning steps to reduce the dimensionality of the data, remove redundant information, and further improve the accuracy. We eliminate all numeric characters and punctuation marks from issue texts. Stop words are words that do not carry significant meaning in a given context and can be safely ignored without sacrificing the overall meaning of a sentence. Examples of stop-words in English include “the”, “and”, “is”, “are”, etc. Similarly, in Turkish, examples of stop-words include “ve”, “ile”, “ise”, “ama”, etc. We use NLTK which provides a built-in list of stop-words for many languages, including Turkish to remove them from issue texts. The last step is lemmatization which is a crucial step in NLP that involves reducing words to their base or dictionary form, known as the “lemma”. The resulting lemma retains the essential meaning of the original word, making it easier to process and analyze text data.
3.3 Feature Extraction
This section describes the feature selection steps for the vectors we created and two popular word embedding methods to compare them. The data set obtained from Jira contains over a hundred important fields that we can potentially use as features. However, a significant number of these fields are empty as they are not filled out by the project’s team. To avoid this issue, we have narrowed down the selection of features to only those fields that are either non-empty for each issue or automatically populated by the Jira system when an issue is opened.
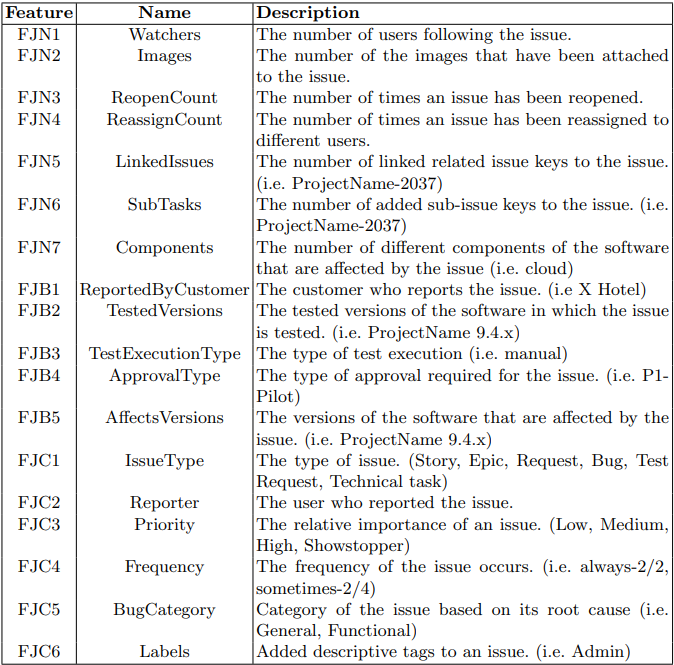
The columns of the issue tracking system are utilized as the initial feature set in our study, as presented in Table 3. FJN indicates the numerical features from Jira ITS. We consider the data numbers in the columns for these values. Watchers are the users who have expressed interest in a particular issue and want to receive notifications about its progress. They can receive notifications whenever a comment is added or any changes are made to the issue. Typically, multiple individuals subscribe to problematic issues in order to receive notifications upon closure or new comments. Images column is used to attach relevant screenshots, diagrams, or other images to an issue. This helps in better understanding and resolving the issue. When a bug cannot be easily identified or located, it is common practice for test engineers to include an image of the bug as a reference for developers. This serves as a visual aid to help the developers understand the issue and resolve it more effectively. Reopen Count column tracks the number of times an issue has been reopened after being marked as resolved or closed. It provides insight into the recurring nature of the issue and can help identify if the issue is resolved properly or not. This feature serves to distinguish problematic issues that persist even after the developer has addressed them. Reassign Count column keeps track of how many times an issue has been reassigned to different users or teams. It can help in analyzing the workflow and identifying any inefficiencies. There are various reasons why an issue may be assigned to someone other than the initially assigned individual. These reasons include cases where the assigned person is unavailable or unable to resolve the issue. The linked issues column allows users to link related issues together. It helps in identifying dependencies and tracking progress across multiple issues. The sub-tasks column allows users to break down larger issues into smaller sub-tasks. It helps in better managing and tracking complex issues. The components column specifies the different modules or components of the software that are affected by the issue. It helps in identifying the root cause of the issue and assigning it to the appropriate team or individual.
We only consider whether or not there is a value present in the column for columns that are mostly empty across the issues and do not have diversity in the data to separate each other. We call these boolean features FJB. Reported by customer column indicates if a customer or an internal team member reports the issue. It helps in prioritizing and resolving customer-reported issues quickly. The tested versions column indicates the versions of the software in which the issue is tested. It helps in identifying the specific version where the issue is first detected. The test execution type column specifies the type of test execution, such as Manual or Automated. It helps in tracking the progress and success of the testing phase. The approval type column is used to indicate the type of approval required for the issue, such as Manager Approval or Technical Approval. It helps ensure that the issue is reviewed and approved by the appropriate stakeholders before being resolved. Affects versions column indicates the versions of the software that are affected by the issue. It helps in identifying the scope of the issue and prioritizing it accordingly.
Several features in our feature set are categorical as FJC, and in order to use them in our analysis, we replaced them with numerical values using label encoding. This process assigns a unique numerical value between 0 and the number of classes minus one to each category, allowing us to use them in our computations. The issue type column defines the type of issue being reported, such as Bug, Improvement, Task, etc. It helps in categorizing and prioritizing issues based on their type. The reporter column indicates the user who reported the issue. It can help in contacting the user for additional information or to gather feedback. The priority column indicates the relative importance of an issue. It can be set to High, Medium, Low, or any other custom value based on the severity of the issue and its impact on the project. The frequency column tracks how often the issue occurs. It helps in identifying patterns and trends in the occurrence of the issue. The bug category column allows users to categorize the issue based on its root cause, such as Performance, Security, Usability, etc. It helps in prioritizing and assigning the issue to the appropriate team or individual. The labels column allows users to add descriptive tags to an issue. It helps in categorizing and searching for issues based on common themes or topics.
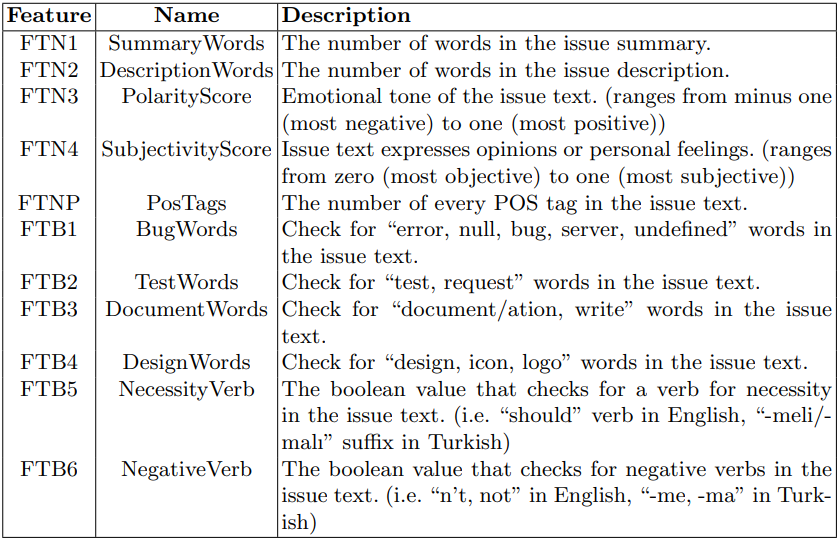
Issue texts are utilized to extract features using NLP techniques, as detailed in Table 4. The FTN column indicates the numerical features extracted from the text fields. The Summary Words and Description Words columns indicate the number of words in the corresponding issue text columns. To analyze the sentiments of the issue texts, the TextBlob library [29] is used for sentiment analysis. Polarity represents the emotional tone of a piece of text, typically characterized as positive, negative, or neutral. The polarity score ranges from minus one (most negative) to one (most positive). Subjectivity, on the other hand, refers to the degree to which a piece of text expresses opinions or personal feelings, as opposed to being factual or objective. The subjectivity score ranges from zero (most objective) to one (most subjective). As described in Section 3.2, each word in the issue text is classified with known lexical categories using POS tagging for the morpheme-related features in both Turkish and English. The number of available tags, such as adjective, adverb, conjunction, verb, numeral, etc., is added as a new feature column for each issue. However, not all tags are added to the table. The most effective POS tags as features are discussed in Section 4.2. The FTB column indicates the boolean features extracted from the text fields. The issue text is searched for Bug Words, such as “error”, “null”, “bug”, “server”, and “undefined” to determine if there is a bug or for the developers. Test Words, such as “test” and “request” are searched for issues created for the test engineers. Document Words, such as “document(ation)” and “write” are searched for the team leaders, and Design Words, such as “design”, “icon”, and “logo” are searched for the designers. The negative verb is a boolean value that checks for negative verbs in the issue text. It is assumed that bugs would be more likely to have negative verbs in their definitions rather than being by design or a new task opened. The necessity verb is a boolean value that checks for the verb for necessity in the issue text (e.g., “should” verb in English, “-meli/-malı” suffix in Turkish).
Word Embedding techniques are used to represent text as vectors. To create vectors, we utilize the preprocessed combination of title and description parts of issues. There are various forms of word embeddings available, with some of the most popular ones being Bag of Words (BoW) [32], Term Frequency-Inverse Document Frequency (TF-IDF) [41] and, Word2Vec [34]. We have implemented Tf-Idf and BOW algorithms using the Sklearn library [38] and the Word2Vec algorithm using the Gensim library [40]. We have tested both BoW unigram and bigram models separately and together. The unigram model stores the text as individual tokens, while the bigram model stores the text as pairs of adjacent tokens. Based on our experiments, the BoW unigram model outperformed the bigram model. This is attributed to the unigram model’s superior ability to capture essential text features.
3.4 Classification
We can train a classifier to attempt to predict the labels of the issues after we have our features. We experiment with various algorithms and techniques when working on a supervised machine learning problem with a given data set in order to find models that produce general hypotheses, which then make the most precise predictions about future instances, possible. We start with using machine learning techniques that Scikit-learn includes several variants of them to automatically assign issue reports to the developers. We try the best-known ML models i.e. Support Vector Machine (SVM), Decision Tree, Random Forest, Logistic Regression, k-nearest Neighbors (kNN), and Naive Bayes (NB). We use Multinomial and Gaussian NB which are the most suitable variants for text classification. The multinomial model offers the capability of classifying data that cannot be numerically represented. The complexity is significantly decreased, which is its main benefit. We test the one-vs-rest model with SVM, a heuristic technique for multi-class binary classification algorithms. The multi-class data set is divided into various binary classification issues. Scikit-learn offers a high-level component called CountVectorizer that will produce feature vectors for us. The work of tokenizing and counting is done by CountVectorizer, while the data is normalized by TfidfTransformer. In order to combine this tool with other machine learning models, we supply the title and description fields that we combined.
Most machine learning algorithms do not produce optimal results if their parameters are not properly tuned so we use grid search with cross-validation to build a high-accuracy classification model. We use the GridSearchCV tool from Sklearn library [38] to perform hyperparameter tuning in order to determine the optimal values for a given model. In particular, we use a 10-fold cross-validation. We first split the issues data set into 10 subsets. We train the classifier on nine of them and one subset is used as testing data. Several hyper-parameter combinations are entered, then we calculate the accuracy and the one with the best cross-validation accuracy is chosen and used to train a classification method on the entire data set.
We also try ensemble learning methods [61] which combine the results of multiple machine learning algorithms to produce weak predictive results based on features extracted from a variety of data projections, and then fuse them with various voting mechanisms to achieve better results than any individual algorithm. First, we use the hard-voting classifier which can combine the predictions of each classifier to determine which class has the most votes. Soft voting based on the probabilities of all the predictions made by different classifiers is also an option. Second, we try a classification method called extra trees, which combines the predictions of multiple decision trees. Finally, we combine machine learning methods with bagging, boosting, and stacking ensemble learning techniques. While boosting and stacking aim to create ensemble models that are less biased than their components, bagging will primarily focus on obtaining an ensemble model with less variance than its components [35].
The majority of classification studies using the issue data set do not use or have limited success with deep learning-based text mining techniques. Herbold et al. [22] believe that they lack sufficient (validated) data to train a deep neural network and deep learning should instead be used for this task once the necessary data requirements are satisfied, such as through pre-trained word embeddings based on all issues reported at GitHub. We try some bidirectional language models: DistilBert, Roberta, and Electra to provide empirical evidence. DistilBert [43] is developed using the Bert [13] model. In comparison to pre-trained Bert on the same corpus, this model is quicker and smaller in size. Roberta [28] is retraining BERT with improved training methodology, more data and compute power. Electra [11] uses less computation than Bert to pre-train transformer networks. In 2022, Guven [20] compares language models for the Turkish sentiment analysis approach and the best performance has been achieved by training the Electra language model. These models are pre-trained with a Turkish data set for Turkish approaches [44].
This paper is available on arxiv under CC BY-NC-ND 4.0 DEED license.
[1] https://www.vestel.com
[2] https://github.com/busrat/automated-software-issues